
Digihumanitaaria on juba mõnda aega olnud kuum lööksõna. Kui läheb arengukavade koostamiseks, rahaküsimiseks jm tähtsaks teadustegevuseks, tuleb seda igas lõigus mõned korrad kasutada. Kui aga küsida täpsemalt, mida see tähendab, võib jänni jääda. Digihumanitaaria hõlmab väga harali ja mitmekesiseid asju: tekstikorpuste, andmebaaside koostamist ja kasutamist, statistilisi meetodeid, uurimistulemuste visualiseerimist ja populariseerimist, aga ka igasuguste digitoodete ja võrgunähtuste uurimist, kirjeldamist, arendamist jne jne.
Arvutuslingvistikat (Haldur Õim jt) ja “kleiomeetriat” (Juhan Kahk jt) on ammuilma tehtud ka Eestis. Aga mida võiks digihumanitaaria meil uuel ajal tähendada? Ingliskeelse maailmaga on asjad selgemad: seal on tõesti väga Big Data väga mitmel pool kättesaadav – ole ainult mees ja kasuta. Tore mänguasi on näiteks Ngram.
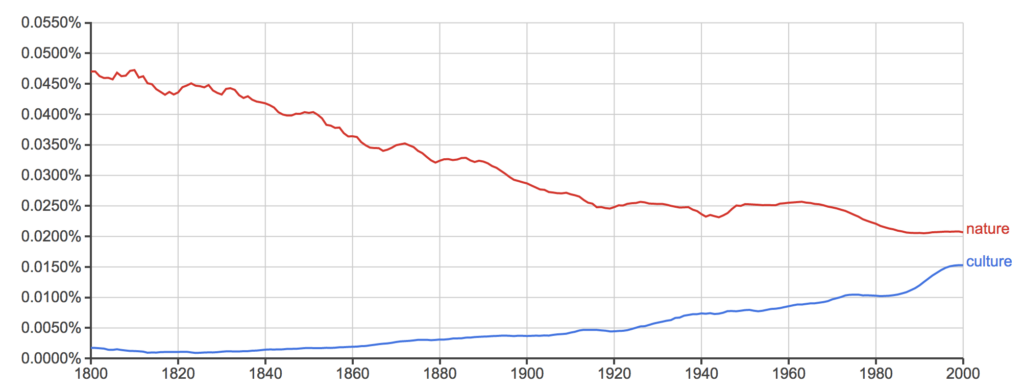
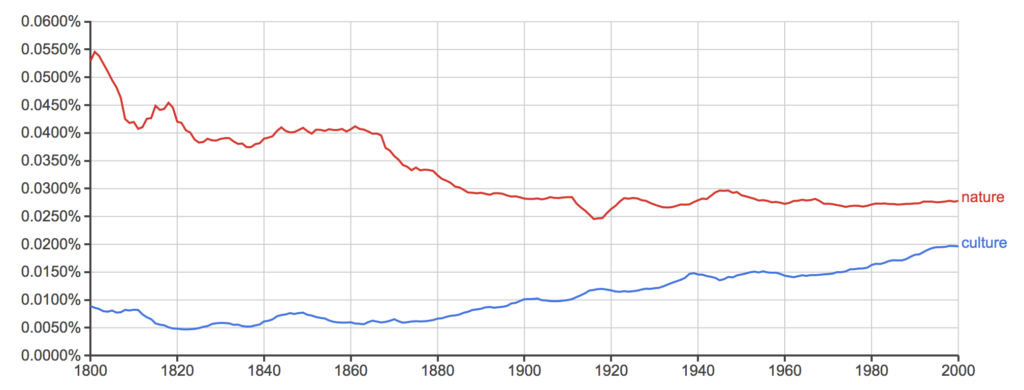
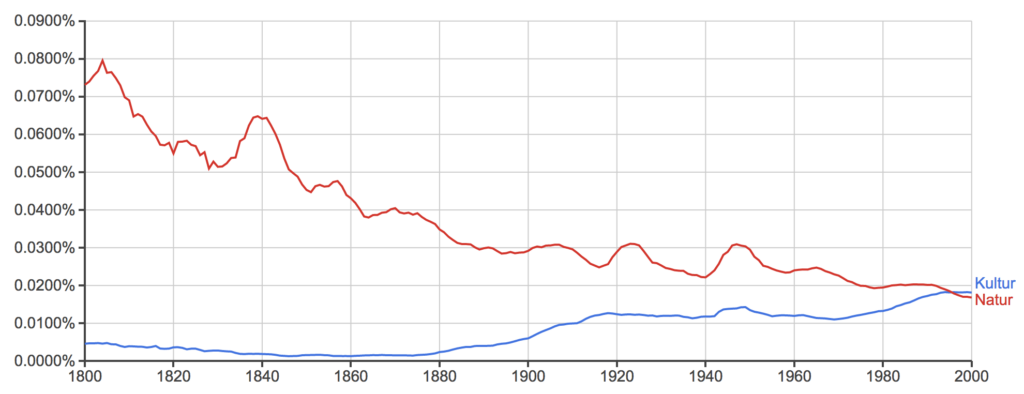
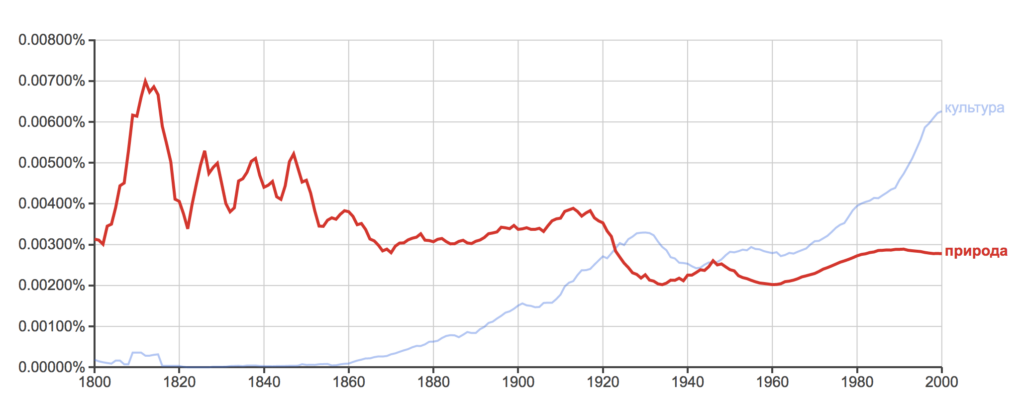
Kui tahta teada, kui palju on viimasel kahel sajandil varieerunud sõnade “kultuur” ja “loodus” kasutus eri kirjakeeltes, selgub, et inglise ja prantsuse keeles on culture olnud tõusu- ja nature langustrendis ning eeldatavasti nende teed peagi ristuvad. Saksa keeles saavutas aga Kultur Natur’i ees edumaa juba 1995. Venelastel oli 19. saj algul tohutu edumaa sõnal природа sõna культура ees, sagedus võrdsustus 1921 ja uuesti 1946 ning sealtpeale on ülekaalus культура.
Inglise:
Prantsuse:
Saksa:
Vene:
Kui pakkuda tuvastatu seletuseks välja paar hüpoteesi, on teadusartikli tuum olemas ning ülejäänu on juba vormistamise vaev.
Paraku ei ole eesti tekstistatistika jaoks Ngramist tolku. Meil on küll olemas mõned lingvistilised tekstikorpused (mida on tülikam kasutada) ja juba päris suur hulk digiteeritud kirjasõna, millest paljugi veel ilma otsinguvõimaluseta.
2013 Norra rahvusraamatukogus toimunud üritusel kõneles selle direktor siira optimismiga uutest perspektiividest humanitaaria jaoks, sest norralased olid lõpetamas kõikide oma raamatute digiteerimisprojekti Arrow. Jagan üldiselt, aga teatud ettevaatusega seda optimismi. Eestis on asi jäänud arvatavasti veel raha, pealehakkamise, koordineerimise ja autoriõiguste taha. Olemasolevad andmebaasid (DEA , Digar , EEVA , eesti värsi korpus , Kirjandusmuuseum jt) on kõik väga toredad, aga enamik neist pole kuigi hõlpsasti statistiliselt töödeldavad. Samas, arvestades, kui vähe on siiski eestikeelseid raamatuid üldse olemas, tundub KOGU kirjasõna digiteerimine väga perspektiivikas. Seda enam, et rahvusbibliograafia on nüüdseks valmis – aga ainult osaliselt digiteerituna ning raskustega töödeldavana.
Aga millist kasu võiks sellest kõigest meie kultuuri mõtestamise jaoks olla? Hoolimata sellest, et aastatagusel “Filoloogia lagunemise” konverentsil kostis nii mõnigi skeptiline sõnavõtt mõõtmiste ja statistika aadressil, arvan, et teatava nutikuse korral avaks täielikult digiteeritud eesti raamat põnevaid uusi perspektiive niihästi nn välise (kirjandussotsioloogia ja -ökonoomika) kui ka sisemise kirjandusuurimise jaoks (stilistika, värsiõpetus). Ja kui sellele lisanduksid veel Eestit puudutavad majanduslik-demograafilised ajaloolised andmebaasid, siis võiks avastada igasuguseid huvitavad korrelatsioone (või nende puudumist), näiteks nisuekspordi ja neliktrohheuse, demograafia ja dekadentsi, inflatsiooni ja avangardi vahel.
Edenenumates ringkondades räägitakse juba tükk aega sellisest asjast nagu “masinõppimine” ja “mustrituvastus”, mis lihtsalt öeldes tähendab arvutite hüppeliselt paranenud võimet andmetest ise korrapära leida ilma neid selleks spetsiaalselt programmeerimata ja ilma et uurija masinale eriti nutikaid küsimusi esitakski. Paul Taylor kirjutas augustis LRB-s selge ja põneva ülevaate, mis nippidega masinad on õppinud andmete põhjal mõisteid moodustama, näiteks google’i piltide põhjal tuvastama kassi nägusid, ilma enne “kassi” ja “näo” mõistet omamata, ning inimest go mängus alistama. Alex Hern kirjeldas poolteist aastat tagasi Guardianis, kuidas mustrituvastus võimaldab masinatel nüüd visualiseerida ka meie “kollektiivset alateadvust”:

Esialgu tuleb vist siiski leppida sellega, et Eesti digihumanitaaria tähendab esmajoones teadusadministratiivset lööksõna või tulevikukava. Mis on ka hea variant, sest järgmisena võib ees oodata igasuguse tõlgenduslikuma humanitaarse lähenemisviisi alavääristamise oht (nii nagu lingvistid ei tahtnud üksvahe tunnistadagi uurimusi, mis ei põhine korpustel). Puhtalt masinjõul tehtud filoloogilised üldistused jäävad sageli triviaalseks, võrreldes inimtõlgendustega. See paistab silma näiteks, kui võrrelda uusmeremaalaste Russell Gray ja Quentin Atkinsoni statistilist arvutustööd indo-euroopa keeleajaloo alal ning Jay Jasanoffi traditsioonilisemat võrdlev-ajaloolist lähenemist . Esimesed uurivad keeleajalugu pealispindselt, sõnavara baasil, ise vastavaid keeli oskamata ning eeldades keele muutumiskiiruse konstantsust. Teine süveneb surnud keeli põhjalikult tundes grammatika peennüanssidesse. Samamoodi vastanduvad nn lähi- ja kauglugemine kirjandusteaduses. Viimane, Franco Moretti eestveetav projekt tuvastada kirjandusloos arengumustreid teatmeteoste ja bibliograafiate kaudandmete põhjal, ise teoseid läbi lugemata, on sellegipoolest avanud huvitavaid perspektiive, mida lähilugemine ei võimaldaks (vt nt Moretti, “Oletusi maailmakirjandusest”, Vikerkaar 2003, nr 7–8). Pealegi ei esita Moretti oma projekti ainuvõimalikuna ning konkreetsemates tõlgendustes demonstreerib ta ka peent lähilugemisoskust.
Ideaalne oleks olukord, kui eesti kultuuri andmebaasid võimaldaksid hakata statistiliselt kontrollima ka igasuguseid tõlgenduslikke hüpoteese (nt kirjandusloo või autori arenguloo teisenemiste või autorite ja voolude maailmavaateliste erinevuste kohta). See aitaks pääseda tõlgendusliku nõiaringi meelevaldsusest (või seda ringi vähemalt avardada) – olukorrast, kus uurija esitab oletuse ja toetab seda heal juhul kümmekonna näitega, küsimata, kui esinduslikud need näited ka on. Üldiselt meie, st humanitaarid tahaksime, et digihumanitaaria IT-poolse külje teeksid meie jaoks valmis teised, itimehed, kes annaksid meile üle juba kasutusvalmis tööriistad. Paraku on see vist liiga utoopiline unistus, pigem tuleks õppida ka ise koodi kirjutama või vähemalt excelitki kasutama. Aga kus ja kui palju?
PS: Digihumanitaariaga seostuvast haibist, blufist ja liialdatud ootustest ning realistlikumatest väljavaadetest ja piiridest andis paari aasta eest poleemilise ülevaate ka Adam Kirch The New Republic’us.
PS PS: Tiit Hennoste annab kolm head vastust digihumanitaaria ühele kesksele küsimusele (eelpool rõhutasin ise just teist põhjust): “Miks on siis üldse vajalik kvantitatiivne analüüs? Kolmel põhjusel. Kõigepealt, kvantitatiivne analüüs saab olla lähtekoht, esimene reha. Selle abil saab selekteerida välja aredate piiridega kooslused, nii sagedased kui ka haruldased. Teiseks on kvantitatiivne analüüs vajalik selleks, et kvalitatiivsel analüüsil leitud mustrite levik üle vaadata ja pääseda sellega välja vaid üksikute tekstide analüüsi nõiaringist. Ja kolmandaks võib kvantitatiivne analüüs olla „järelabi”.”